Validation of Machine Learning Libraries
Tuesday, February 25, 2020
More and more manufacturers are using machine learning libraries, such as scikit-learn, Tensorflow and Keras, in their devices as a way to accelerate their research and development projects.
However, not all manufacturers are fully aware of the regulatory requirements that they have to demonstrate compliance with when using machine learning libraries or how best to do this. This leads to unnecessary outlays or unexpected difficulties during audits and authorities, delaying device authorization.
Content overview |
This article will help manufacturers and auditors to understand what they should pay attention to when validating machine learning libraries. It will also explain which requirements (e.g., from the authorities and notified bodies) lack any legal and logical basis.
You will also learn how to discuss issues on equal terms and how you can avoid unnecessary and unjustified requirements, thereby saving time and effort and ensuring that you can place your device on the market without any problems.
Note on authorship: Prof. Dr. Oliver Haase is the co-author of this article. He is also the head of the “Artificial Intelligence in Medical Devices” seminar and provides support to Johner Institute customers for the validation of machine learning libraries.
1. Machine learning libraries: a quick introduction
Machine learning libraries provide manufacturers with the majority of the functionality required to use machine learning and artificial intelligence techniques in their devices.
These techniques include neural networks, regression (e.g., logistic regression), tree ensembles (e.g., Random Forrest, XGBoost) and support vector machines.
Manufacturers use these methods to classify data (e.g., images, text, data in tables) to decide, for example, whether an image contains a melanoma or not, or to make predictions, for example, regarding the best dose of a medicine.
Further information
You can read more on the application of artificial intelligence in medicine here.
The libraries are not just used for the development and application of machine learning. They also help with data preparation and data analysis.
Most machine learning libraries have their origins at universities but these libraries are being replaced by libraries from US tech giants. For example, Tensorflow and PyTorch were developed by Google and Facebook, respectively.

2. Regulatory requirements for the use of machine learning libraries
The most important regulatory requirements that manufacturers, notified bodies and regulatory authorities should pay attention to in a machine learning context include:
- MDR/IVDR: Requirements, among others, regarding
- The repeatability, reliability, robustness, and proven performance of the device
- Software life cycle processes, risk management, etc.
- IEC 62304: Requirements, among others, regarding
- The planning and documentation of development
- The verification of code and documents
- The use of SOUP components
- ISO 13485: Requirements, among others, regarding
- The competence of the development team and
- The validation of computerized systems, processes and tools
Comparable requirements apply in the USA. The FDA refers to OTS rather than SOUP. But the two terms are not quite the same.
The US authority has published a “Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD)”, which is only of limited relevance for the specific context.
3. The role of machine learning libraries in device development
Manufacturers use machine learning libraries in all phases of research, development and application of the device: from the collecting and pre-processing of the data to training the model through to the use of this model in the delivered device.

From a regulatory perspective, these phases can be divided into two areas.
a) Development and training of the model
The first part involves the development of the model, i.e., selecting the right technique and choosing the best possible hyperparameters.
If the code for this data pre-processing and the training of the model is not part of the medical device (this is usually the case), IEC 62304 is not(!) applicable. This applies both for the development of this code as well as the use of existing machine learning libraries (SOUP).
However, manufacturers have to comply with the requirements of ISO 13485, e.g., with regard to the computerized system validation. The validation of the machine learning libraries is part of this.
N.B!
The aim of a machine learning library validation is not(!) to demonstrate that the model will subsequently make correct predictions in the field.
Nor does the machine learning library validation have to demonstrate that the model is the most suitable, nor that the manufacturer has chosen the best hyperparameters.
Instead, this step is about proving that the library has “fitted” the best parameters for the selected model, for the specified hyperparameters and for the training data used.
For example, for a logistic regression, a manufacturers would have to demonstrate that the matrices with the weights and intercept vectors are suitable for the given training data.
Further Information
Please pay attention to the article on computerized system validation in this context.
b) Application of the model
The trained model now becomes part of a (medical) device together with the machine learning library (or part of it). This component is now responsible for making correct predictions, e.g., for correctly classify images.
This component is a SOUP. Therefore, the manufacturer must demonstrate that the corresponding requirements of IEC 62304 regarding SOUPs have been met. This includes the obligation to specify and verify the requirements that apply to the SOUP.
IEC 62304 rightly calls this the verification of the SOUP/component, even if the term validation is used more often when talking about libraries.
This verification/validation step involves demonstrating that the component makes the correct prediction with respect to the trained model.
Again, this machine learning library validation is not about proving that the model makes correct predictions compared to the “ground truth”.
Therefore, manufacturers should not validate the component by testing that the component provides the expected result for correctly “labeled” test data.
Instead, manufacturers should test whether the specific model (e.g., the logistic regression with its parameters) gives the mathematically expected output for each valid input data vector.
4. Best practices for the validation of machine learning libraries
a) Preliminary considerations
Like any component, a machine learning library provides an encapsulated functionality via well-defined interfaces.
The unique feature of machine learning libraries is that most of this functionality and these interfaces is used for the training and optimization of the model, and only a small part is used in the device during its life span. Often this is only one method, e.g., predict().
As shown above, different regulatory requirements apply for the training and the application of the model. Manufacturers should take advantage of this technical and regulatory split. It means that the validation of machine learning libraries can be split into several independent task blocks:
- Data preparation (scope of ISO 13485)
- Training of the model (scope of ISO 13485)
- Application of the model (scope of IEC 62304)
Depending on the use case, there may be other software applications and components, e.g., for the labeling of the data. However, this would go beyond the scope of this article.
b) Ad 1 . Validation of the data preparation
The typical activities involved in data preparation include:
- Handling of invalid data
- Handling of missing data
- Format conversion
- Conversion from continuous to discrete values
- Normalization of data
The easiest and quickest way of checking these data processing steps is to use “normal tests”. These tests should be implemented as code in order to be permanently available as regression tests.
The standard black box test methods, such as equivalence class, limit or fault-based testing should be used as the test methods. Testing a “happy path” is not enough.
In order to use these test methods correctly, we recommend using descriptive statistics to get a more precise understanding of the data.
c) Ad 2. Validation of model training
As explained in section 3.a), in this step the manufacturer must demonstrate that the library has “fitted” the best parameters for the selected model, for the specified hyperparameters and for the training data used.
With simple models in particular, this proof can be provided as a graph showing the actual and fitted values. More complex models often require projections in lower dimensions.
Fault metrics (e.g., r2, p) help quantify the quality of the model for the given training data. Machine learning libraries can actually determine these metrics but, strictly speaking, this would require the correct calculation of the metrics to be validated beforehand. However, you then run the risk of expending wasted efforts that no longer deserve the attribute “risk-based”.
N.B!
Manufacturers should not succumb to the temptation of overfitting by minimizing these faults. This would reduce the performance of the model “in the field”.
d) Validation of model application
Manufacturers must specify and verify/validate the functions of the machine learning library used in the medical device in accordance with IEC 62304. This process should include the following:
- Defining the requirements for these functions. As a general rule, this can be a method (predict) that calculates the correct values for a given model.
- Specifying the requirements for the use of the machine learning library. These are mostly programming languages and hardware requirements.
- Selecting the machine learning library (including exact version) that meets the requirements and prerequisites.
- Researching the anomalies in these libraries and evaluating their acceptance.
- Verifying/validating that the library - more precisely the corresponding function(s) - meets the specified requirements.
An auditor can request documentation of all these steps. The last step may be the most challenging, not in terms of its documentation but in terms of its implementation:
An input vector with 30 features, each of which can only take seven values, would already give 2.3 x 1025 values. It’s impossible to test.
Incidentally, the reduction to seven values could be achieved by creating equivalence classes.
In order to control the explosion of combinations, subset testing, e.g., paired testing, is used. The more parameters that are tested in combination, the higher the probability of finding faults (see Fig. 3).
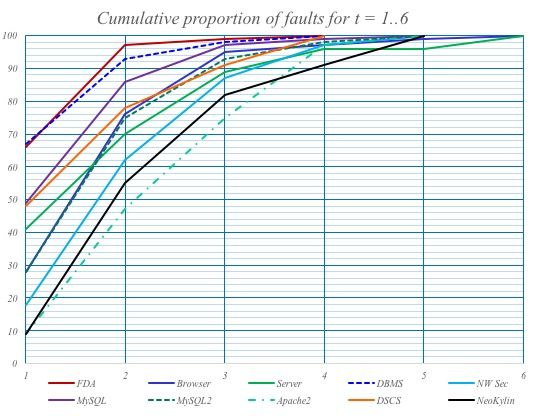
To perform these tests, you also need the software to generate the test data, not just the test code.
Tip
The Johner Institute has already developed such code and validated some libraries.Just get in touch, for example, if you would like some support for the validation of your machine learning libraries.
5. Digression: comparison with “model-driven software development”
The European medical device regulations do not explicitly address artificial intelligence and machine learning. It is, therefore, helpful to look at comparisons with proven technologies and approaches. This includes “model-driven software development”.
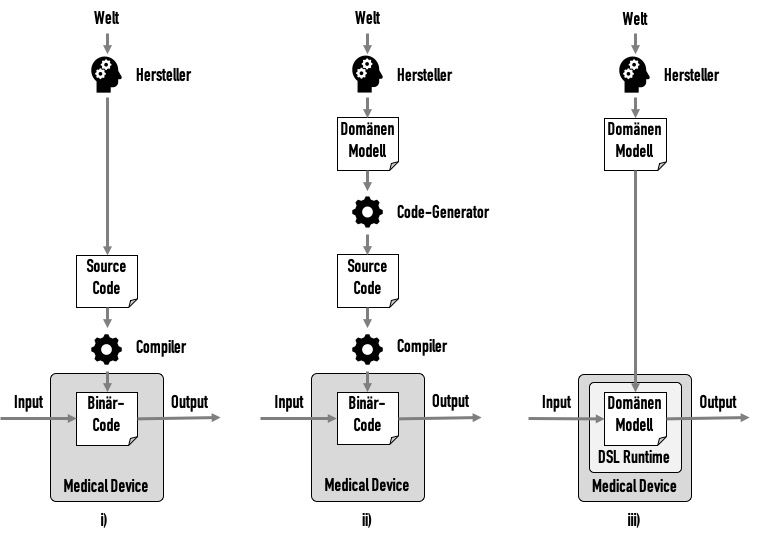
a) Quick introduction to “model-driven software development” (MDSD)
i) Classical development
In classical software development, a manufacturer tries to gain an understanding of a domain, to develop a model of this domain and to implement this in code. (See Fig 4.i))
For example, a model may state that a patient is a human who has one or more diseases. In this case, the code would have a “patient” class that references a collection of “illness” classes.
This source code would be converted into binary code by a compiler, and this binary code would become part of the medical device.
The validation of this compiler can usually be skipped based on risk considerations, e.g., because the compiler has been tried and tested over a long period and therefore faults are unlikely or because faults would be noticed sufficiently frequently during the compilation process.
ii) Model-driven software development 1
The next step would be to first create a domain model in a domain-specific language (DSL). A code generator would automatically convert this into source code. This code generator would be a computerized system to be validated in accordance with ISO 13485. (See Fig. 4.ii))
iii) Model-driven software development 2
The next step in evolution would be to skip the intermediate code generation step. A “runtime” for the model would be used instead. In other words, the model would be executed directly in the medical device. (See Fig. 4.iii))
This DSL runtime would be a software component that, like any other software component, has to be specified and verified. Whether the manufacturer develops this component itself or uses a SOUP is secondary.
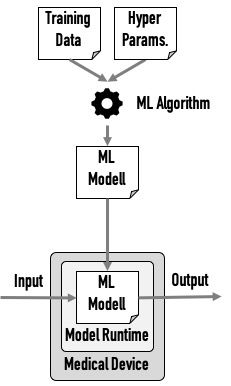
b) Comparison with machine learning
Comparable approaches can be found in machine learning:
- Here too artifacts, namely models, are generated automatically and later used in a device. And there is also a runtime for the model.
- Both the model generation and runtime are supported by libraries - the machine learning libraries.
- In a sense, the data scientists also develop a program, a domain model, at a higher level of abstraction.
- Just like the code generator, the model generator has to be validated according to ISO 13485. And just like the DSL runtime, the use of the model runtime has to meet the requirements of IEC 62304.
6. Conclusion and summary
a) Please use the libraries
Manufacturers who want to use artificial intelligence methods such as machine learning in their devices should use existing libraries. There are several reasons for this:
- You save time. The development of these machine learning libraries is likely to have involved decades of work for a lot of people.
- You improve quality: The libraries have been used hundreds of thousands of times. This means that users around the world find and report bugs and help fix them quickly. The bug lists mean these libraries are transparent.
b) Ensure expertise
The use of machine learning libraries requires technical and regulatory expertise. This expertise is required by ISO 13485 and the MDR. But it does not always seem to be guaranteed.
For example, some auditors' claims that the SOUP/OTS requirements must be met, with the exception of the predict function, are incorrect.
In addition, the claim that the manufacturer must prove the accuracy of the model during the validation of machine learning libraries often shows a lack of understanding.
The validation of the libraries must and can be done independently of the validation of the device. The objectives are fundamentally different.
c) Take a risk-based approach
Manufacturers must study the requirements and follow them precisely. Software, including machine learning libraries, should be validated using a risk-based approach. The probability of a bug in your own code is usually orders of magnitude than the probability of one in a tried and tested library.
In addition, it doesn’t state anywhere that the library has to be validated in its entirety. The regulations state that the requirements actually used must be checked. These usually represent only a small subset of the overall functionality.
A risk-based approach also means that the device and the library (SOUP/OTS) have to be continuously monitored on the market.
d) Do not reinvent the wheel
Just as it useful to reuse existing libraries, it is also helpful to look at existing validations of machine learning and their post-market surveillance.
There is no need to reinvent the wheel. Please let us know if you want to reuse our work.

Author:
Prof. Dr. Christian Johner

Back To Top
Privacy settings
We use cookies on our website. Some of them are essential, while others help us improve this website and your experience.