Transfer Learning in Medical Devices: Regulatory Recklessness or an Ethical Necessity?
Transfer learning is an approach to machine learning in which models trained with a dataset from one domain (pre-trained models) are used in a different domain after “re-training”.
This can save more than just redundant training work. However, it does mean that manufacturers have to be prepared for new questions from auditors and reviewers.
1. Transfer learning: what is it?
a) Deep neural networks
Transfer learning is mainly used with deep neural networks (DNN). These networks often consist of hundreds of layers, which themselves contain hundreds or thousands of neurons. This means that millions of parameters (e.g., weights and thresholds) have to be defined when training these networks.
The different layers are able to perform different tasks after the training: for example, in the case of DNNs trained with images, the lower layers recognize simple geometric structures, such as edges. Higher layers can detect increasingly complex structures. The last layer, the output layer, is generally used for classification. In other words, it gives the probability that an input falls into a particular class, e.g., an image contains a particular object (see Fig. 1).
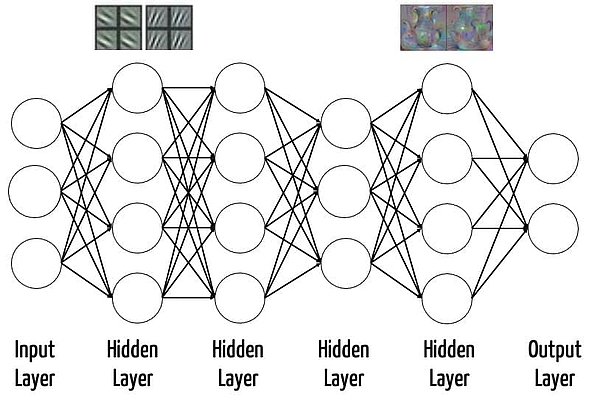
In medical diagnostics, this last layer would classify different images, for example, dividing them into malignant and benign changes or determining the likelihood of a stroke or a cancer.
Additional information
Read more about artificial intelligence and machine learning for medical devices here.
b) Transfer learning from pre-trained models
The lower layers are usually not very specific to the domain: image recognition almost always requires the recognition of simple geometric structures. Therefore, it makes sense to reuse some of these layers that have already been trained and to “re-train” the other layers with input data from the specific domain.
This transfer of pre-trained models from one domain to another is called transfer learning.
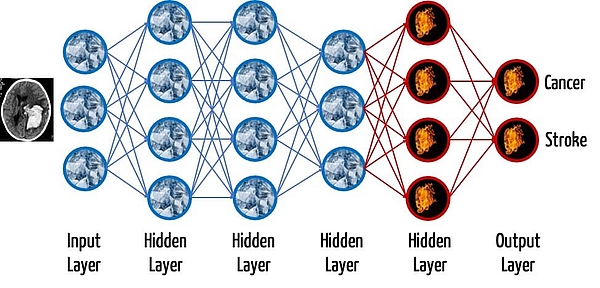
The last layer, the output layer, is always removed. This is because the classification is highly specific to the particular application. If, for example, a model is able to distinguish between two different diseases, then the output layer must consist of two neurons.
How many layers you re-train and how many you leave unchanged depends on the size of the dataset and the similarity of the input data in the two domains.
You can find more information on this in an article on “Transfer learning from pre-trained models”
2. Advantages of using pre-trained models
Training a model, especially a DNN with a lot of weights, is a time-consuming task:
- Training data has to be found. The image database ImageNet has collected more than 14 million images over the years.
- In the next step, the images then have to be labeled: in other words, someone has to go through the images and “manually” decide what they show. With 14 million images, that’s a labor-intensive step.
- Then the best machine learning method and the best architecture for it has to be found.
- Finally, there are other “hyperparameters” to test.
The last two steps require resource-intensive training of the models and corresponding powerful and power-hungry hardware. These training processes often take days or weeks.
The time spent on these steps can be reduced by transfer learning, i.e., by using pre-trained models.
But the learning efficiency is not the only advantage: there is often not enough training data available. This is the reason why a manufacturer starting from scratch simply cannot achieve the performance (e.g., sensitivity) of a pre-trained model.
3. Risks of transfer learning
a) Suboptimal model
Every manufacturer aims to develop the best model possible. To do this, they have to compare various models. In other words, the manufacturer has no choice but to test out these models: to develop, to train and to evaluate them. This comparison is time-consuming.
In addition, pre-trained models are not generally better. It is often possible to achieve at least comparably good, sometimes even better results, by using smaller, specialized networks that have been specially trained.
How big the benefit is depends on how similar the dataset it to the one the model was pre-trained with. Since radiological images are very different to images in databases such as ImageNet (e.g., content, colors), manufacturers are often only left with the trial-and-error approach to finding the best model.
b) Compromised data protection
In some cases, it is possible to extract information from the training data even with large models. To do this, an “attacker” doesn’t even need to have access to the inner workings of the model. as a study by Google and several US universities has shown.
In the case of medical data, it would be particularly damaging if conclusions about the training data and, therefore, the health data of individual patients, could be drawn from the model's output.
c) Compromised data security
Another attack could target the training data. A different study has shown how training data (in this case, images) for a pre-trained model can be invisibly modified in a way that subsequently leads to incorrect classifications.
Using the example of texts, it has been shown that it is possible to build a “backdoor” into the training data (in this case texts). This backdoor causes the model to classify an input text in the way the attacker wants if it contains a keyword defined by the attacker – irrespective of the rest of the text, which would otherwise be classified differently.
Since a lot of models are pre-trained using publicly available data, such attacks are more likely to be a risk when using public data than when a manufacturer uses data it has exclusive control over.
d) Other risks
Pre-trained models can have the same weaknesses as self-trained models, for example:
- Incorrect predictions due to overfitting
- Incorrect predictions for certain input data due to bias in the model
- Only randomly correct predictions
- And many more
4. Regulatory evaluation of transfer learning
a) Model = software?
A pre-trained model consists of a model architecture and the fitted values (e.g., weights, thresholds). Standards such as ONNX enable models to be exchanged even between different libraries, such as PyTourch, Tensorflow, or Keras (which is based on Tensorflow).
But isn’t a model more like data?
The MDCG defines software as follows:
Definition: Software
“For the purpose of this guidance, “software” is defined as a set of instructions that processes input data and creates output data.”
Source: MDCG 2019-11
So, the model itself would not be software. Other definitions, however, see it differently:
Definition: Software
“… (complement to ‘hardware’ for the physical components) is a collective term for programs and the associated data.”
Since it is irrelevant to the result whether it was generated through explicit instructions or through a combination of parameterized instructions and these parameters, it makes sense to consider the model and the corresponding executing library as software.
b) Model = SOUP?
It is, therefore, obvious that the machine learning library (at least the part that makes predictions with the help of the model) and the unmodified part of the model should be considered SOUP (software of unknown provenance) since they become part of the medical device.
The difficulty here is that the model and its data, as SOUP, do indeed form a software component. But the interfaces of these components are neither difficult to specify nor testable in isolation.

c) Documentation
During its consultancy work, the Johner Institute has noticed that manufacturers are using pre-trained models without addressing the fact, and sometimes even without validating them. Both represent a failure to comply with the requirements of IEC 62304 and mean there is no basis for sound risk management.
d) Risk Management
Transfer learning regularly helps manufacturers accelerate the development and training of ML-based models. However, this can lead to specific risk management requirements:
- In order to optimize the benefit-risk ratio, a diverse range of variants must be evaluated. This “diversity” refers to:
- With and without pre-trained model
- The proportion of pre-trained areas that are removed and re-trained
- Deciding whether to re-train areas that have already been trained (in other words, are already trained areas “frozen” or not?)
- The manufacturer must identify and manage the risks resulting from transfer learning, including the risks already mentioned above:
- Compromising of data security as a result of attacks on the training data and thus the model's parameters
- Suboptimal results due to a bias in the pre-trained model’s data
- Misclassification of unexpected input data or input data that is randomly (mis)interpreted as a feature in the pre-trained layers
- Misclassifications due to incorrect labeling of the pre-trained model’s training data
e) CSV
One difficulty common to all ML libraries remains: different regulations define how different parts of a library should be considered:
- One part falls under the scope of ISO 13485 and must therefore comply with the requirements for the validation of computerized systems
- Another part must comply with the requirements of IEC 62304
This division is based on functionality.
Additional information
Read more on this topic in the article on the validation of ML libraries.
5. Conclusion
Transfer learning is becoming more popular. This is also due to the fact that similarly good results can be achieved very quickly with pre-trained models.
But, for medical device manufacturers, the requirements are more stringent: “good enough” is not enough. Instead, manufacturers have to make a justified argument that the approach they have chosen leads to the best performance and thus the best benefit-risk ratio.
In some cases, it can be assumed that transfer learning leads to the best results because it is based on the largest possible training dataset. This would include, for example, fine-tuning a model for the slightly different image data provided by imaging modalities (e.g., CT, MRI) from different manufacturers.
The demands on auditors' technical understanding and the manufacturers’ knowledge of the current state of the art continue to increase. The Johner Institute’s guidelines, which the notified bodies used modified version of, can help both sides reach a common understanding (of the requirements).
With these guidelines, the regulatory risks are manageable. Manufacturers should experiment with the opportunities offered by transfer learning so that can be more confident that they have developed the safest and best performing model for the specific application.
Additional information
We recommend listening the podcast on this topic with Professors Haase and Johner.
The Johner Institute can support medical device manufacturers in the legally compliant use of machine learning methods. Please feel free to contact us.

Author:
Prof. Dr. Christian Johner

Back To Top
Privacy settings
We use cookies on our website. Some of them are essential, while others help us improve this website and your experience.